
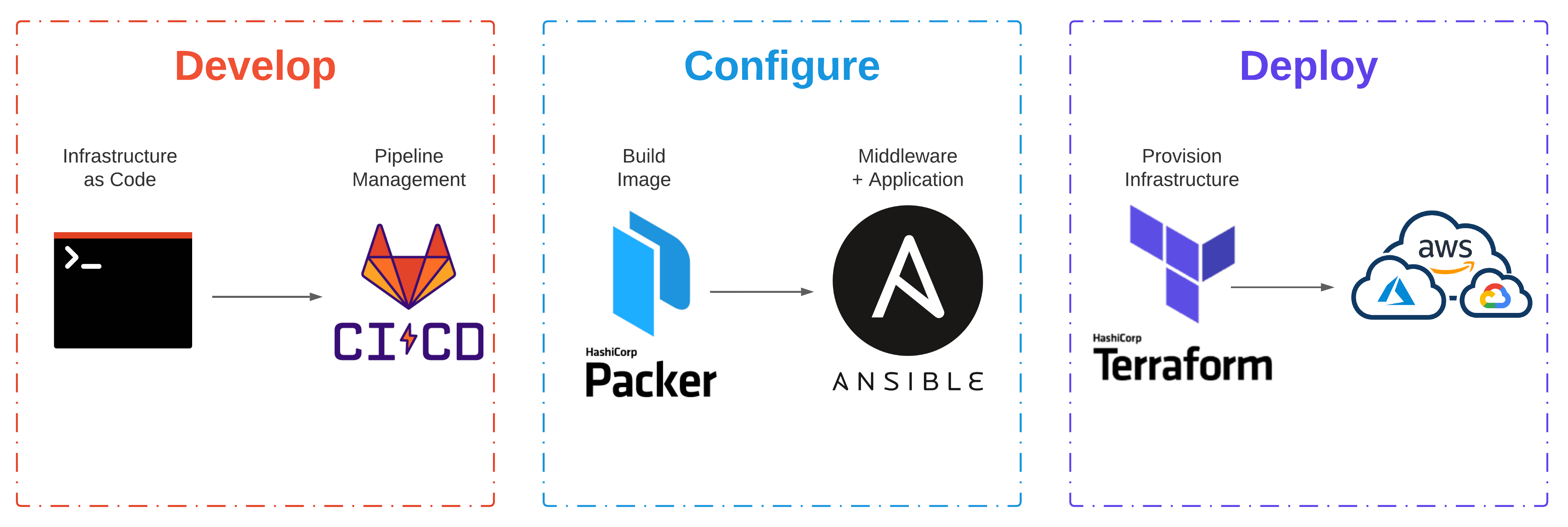
Manually provisioning infrastructure slows down application delivery, isolates knowledge, can hamper operations teams, and doesn’t scale. Automating infrastructure provisioning can address these challenges by shifting manual process into code. Hashicorp has products spanning the infrastructure, security, and application stack that can unlock that cloud operating model and deliver applications faster.
Let’s examine image lifecycle management and IaaS deployment. Both of these tasks are common challenges faced by the enterprise when moving to the cloud. Using Packer, we can automate the build process for images and then deploy common infrastructure and virtual machines with Terraform.
What Is Cloud Grade Automation?#
I started using this expression as a catch phrase some time back, mainly in Powerpoint slides. The way I would describe its meaning goes well beyond a single tool, process, or methodology. To me, it embodies the core guiding principles for cloud and application delivery in today’s landscape. Let’s start with the outcomes we are aiming for:
- Loosely coupled application architecture; Cloud Native
- Infrastructure hosting a given application is delivered intact
- Infrastructure is never touched, changed, or otherwise modified in any way
- When changes are necessary, the environment is re-deployed from the newest artifact
- Rollback occurs in the same way except with an older versioned artifact
The culture, tooling, process, and delivery that can achieve these outcomes, is my impression of what Cloud Grade Automation is. I’ll be focusing specifically on the tooling and delivery in this post.
Evolving Automation#
Automation can typically be handled at two different stages of a given workflow. Choosing which stage can ultimately drive operational decisions. As application architectures have evolved, the automation used to build the infrastructure has transformed. Complexity has largely shifted from runtime to build-time.
Runtime - (Mutable)#
When we think automation, folks that have been around a while typically think in terms of mutable. This means we deploy our server and then configure, update, or modify it in-place. I have seen anything from scripts (Shell, Perl, and Python) to configuration management tools like Ansible, Chef and Puppet used to accomplish this.
Webster defines mutable as ":prone to change: INCONSTANT".
To further expand on runtime configuration, let’s take the example of installing an agent-based solution. For the sake of demonstration, let’s say that each virtual machine provisioned in our infrastructure requires running ThousandEyes - Enterprise Agents for monitoring.
- A greenfield application is getting developed; New infrastructure is required (Develop)
- The new server (or multiple servers) are provisioned for the application to run on (Deploy)
- Config Management tooling applies the standard configuration, including the Agent (Configure)

Mutable infrastructure is susceptible to configuration drift. As individual changes get applied on servers throughout their lifecycle, the configuration will significantly differ from the desired state and other servers across the environment.
Build-time - (Immutable)#
Immutable infrastructure aims to reduce the number of moving pieces at runtime. Handling infrastructure this way speeds up delivery, eliminates configuration drift, increases environment consistency, optimizes rollback, and simplifies horizontal scaling.
Webster defines immutable as ":not capable of or susceptible to change".
To further expand on build-time configuration, let’s take the same example used above:
- A greenfield application is getting developed; New infrastructure is required (Develop)
- The standard configuration and Enterprise Agent get packaged at build-time (Configure)
- Infrastructure is provisioned using the machine template and deployed at runtime (Deploy)
Building immutable infrastructure can be a significant undertaking when considering the transition of brownfield applications. One dependency ensures that the application layer remains stateless, including servers. Anything at this level should and will be consistently destroyed and rebuilt.
Getting Started With Packer#
Packer automates the creation of any machine image. Once the image is packaged, it can then be provisioned with Terraform. While this is the new, modern, cool, and cloud way to accomplish this, other methods have existed for a very long time. Back in 2014, I was doing non-interactive installs of various Linux distributions on Linux KVM with virsh and virt-install. Virt-install would use libvirt’s streaming API to upload the kernel and modified initrd to the remote host.

Building A Machine Image#
As an example, let’s package an Ubuntu 18.04 image with a ThousandEyes - Agent. Although an overly simplistic example, it should demonstrate our desired intent and behavior. Demo code can be found here.
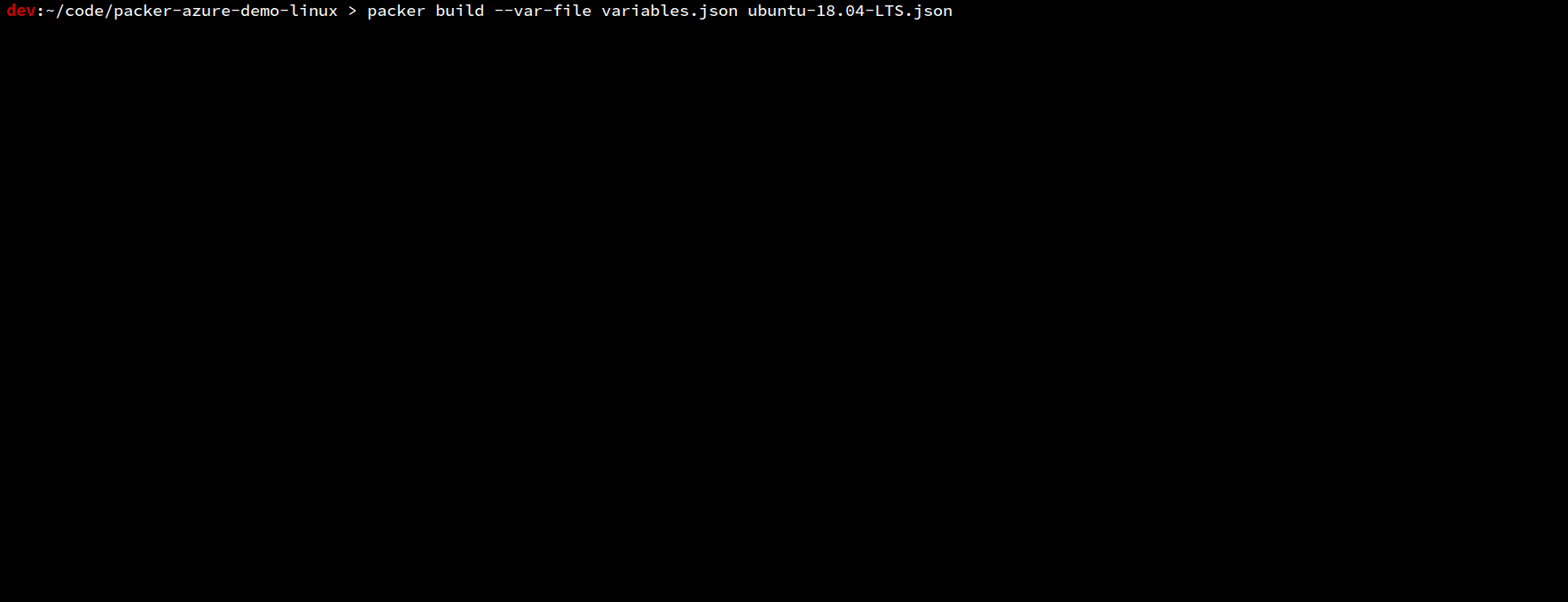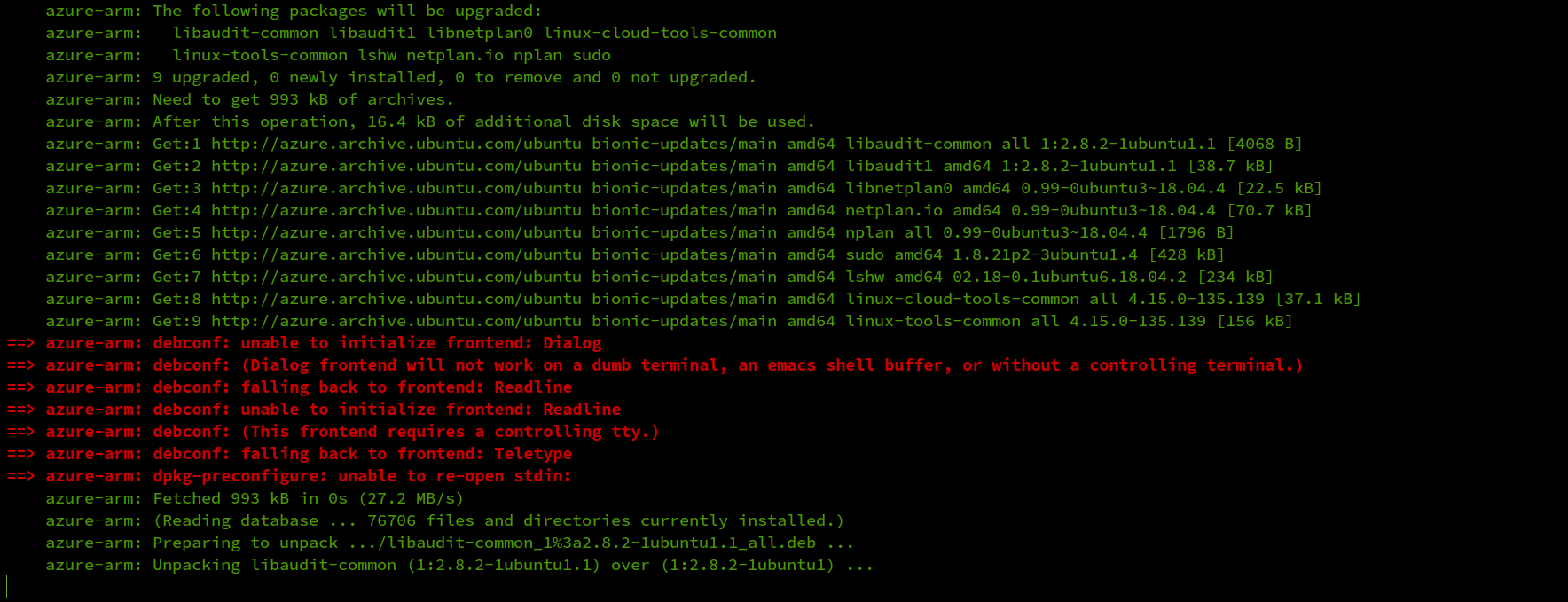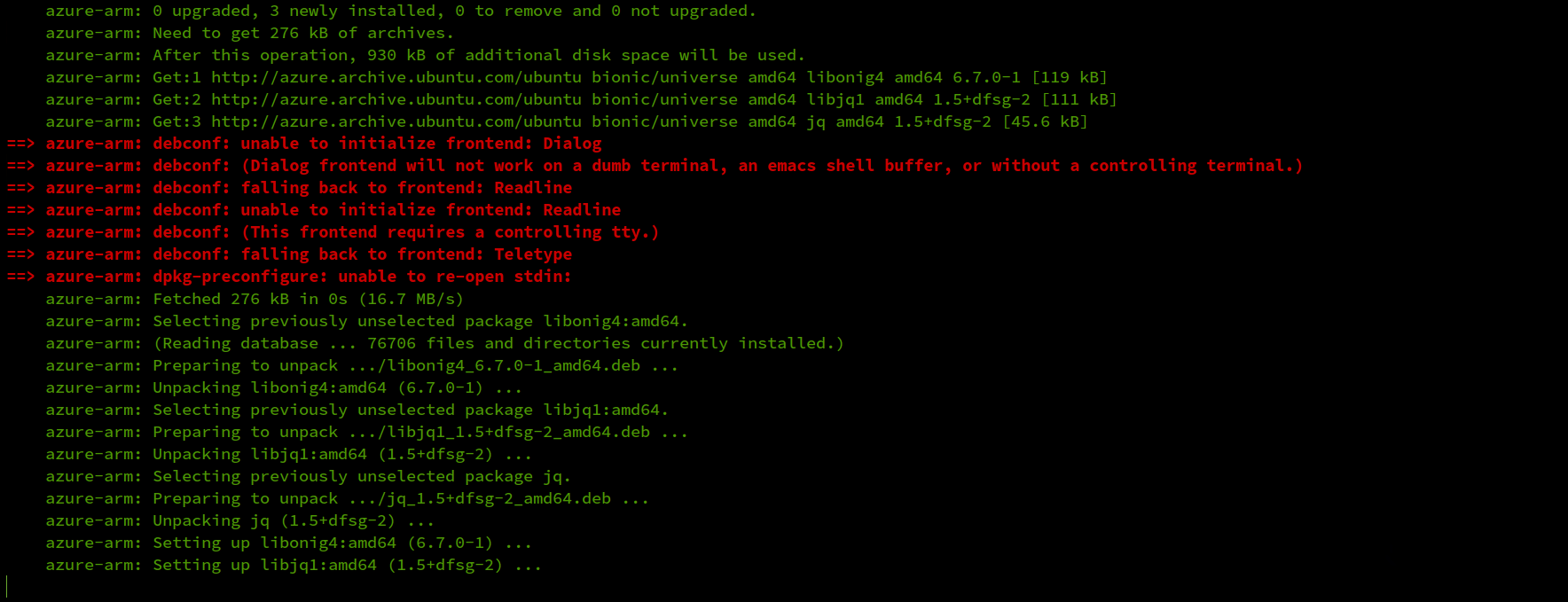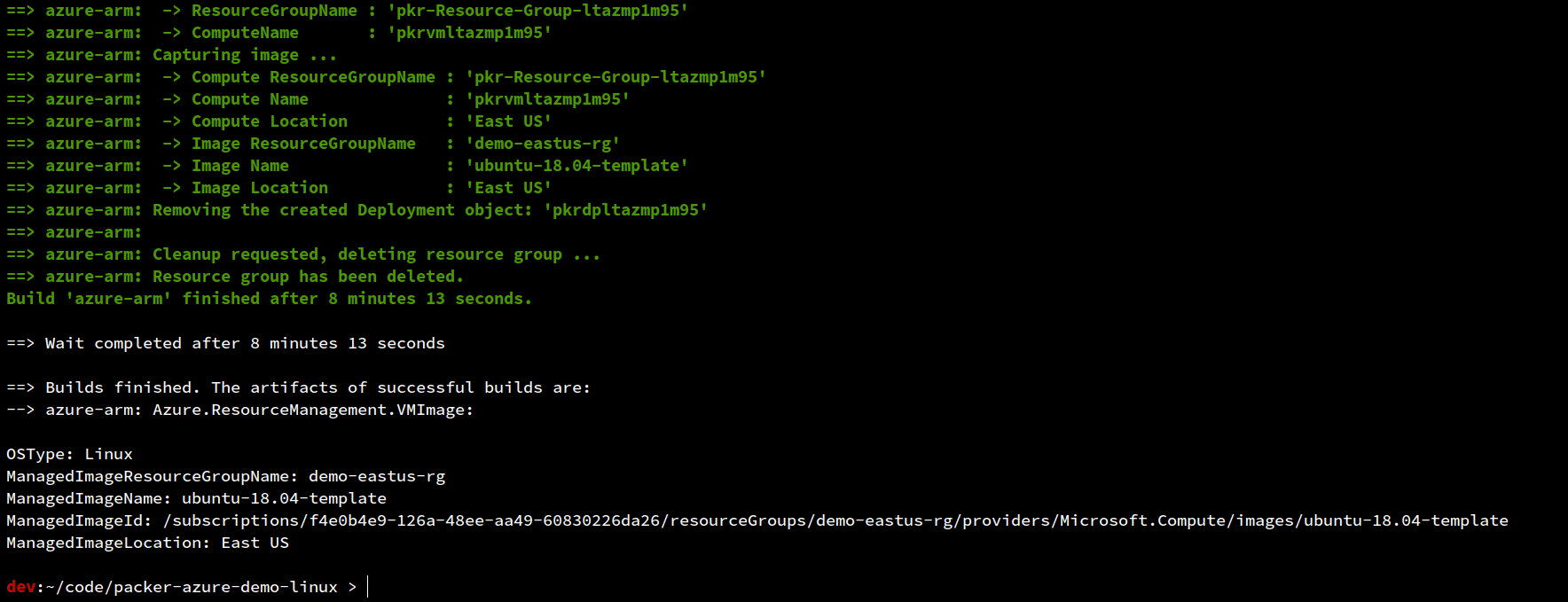
| |
Instead of using the shell provisioner to deploy the agent (see line 35 in the template), a more elegant method would call the “type”: “ansible” provisioner pointing to a playbook.yml file in the repository. This would allow you to separate packages into separate playbooks managed in version control.
Getting Started With Terraform#
Terraform codifies cloud APIs into declarative configuration files. If you want to create reproducible infrastructure for consistent testing, staging, and production environments with the same configuration, look no further! While it’s generally not that simple, Terraform does seem to be the defacto tool these days for Infrastructure as Code in the cloud.
Deploying Some Infrastructure#
Let’s deploy some foundational infrastructure along with a virtual machine provisioned from the machine image we built above with Packer. Demo code can be found here.

| |
This template is an example. In practice, this would probably be broken up into at least two distinct modules (network and compute). If specific groups of resources have a similar life cycle, you would probably create a module for them. An example of this might be core network components like VNets, Subnets, and UDRs.
Conclusion#
Learning to use Packer or writing Terraform templates is a tiny piece of a vast puzzle. If the desired outcome is Continuous Delivery then application architecture, cultural philosophies, and release management all play equally important roles.
Enterprise Leaders all want DevOps for the benefits of automation, quicker releases, reduced downtime, reliable recovery from disasters, and cost benefits in the cloud (That last one makes me chuckle). The real question is, will they do what is necessary to buck traditional culture and adopt truly immutable infrastructure?