
In Part 1, we went over some fundamentals. For Part 2, we will examine Azure network design patterns based on cloud maturity and organization size. The concept of design patterns was first introduced by Christopher Alexander and has profoundly influenced many technical disciplines.
To keep things simple, let’s define a design pattern as a reusable solution to a commonly occurring problem. Of course, you are not the first practitioner out there transitioning to cloud or growing to a new maturity model. Many trailblazers have already walked the walk and left behind beautiful blueprints to help you along the way.
Patterns Overview#
While every scenario may not fall under these categories, there are generally three phases that your cloud network may likely go through as your organization matures.
- Island - Starting point or cloud native panacea; Disconnected from the enterprise network
- Hybrid - Often inevitable (integration requirements); Connected to the enterprise network
- Hub & Spoke - Stemmed by growth and need for centralized control; Increased governance
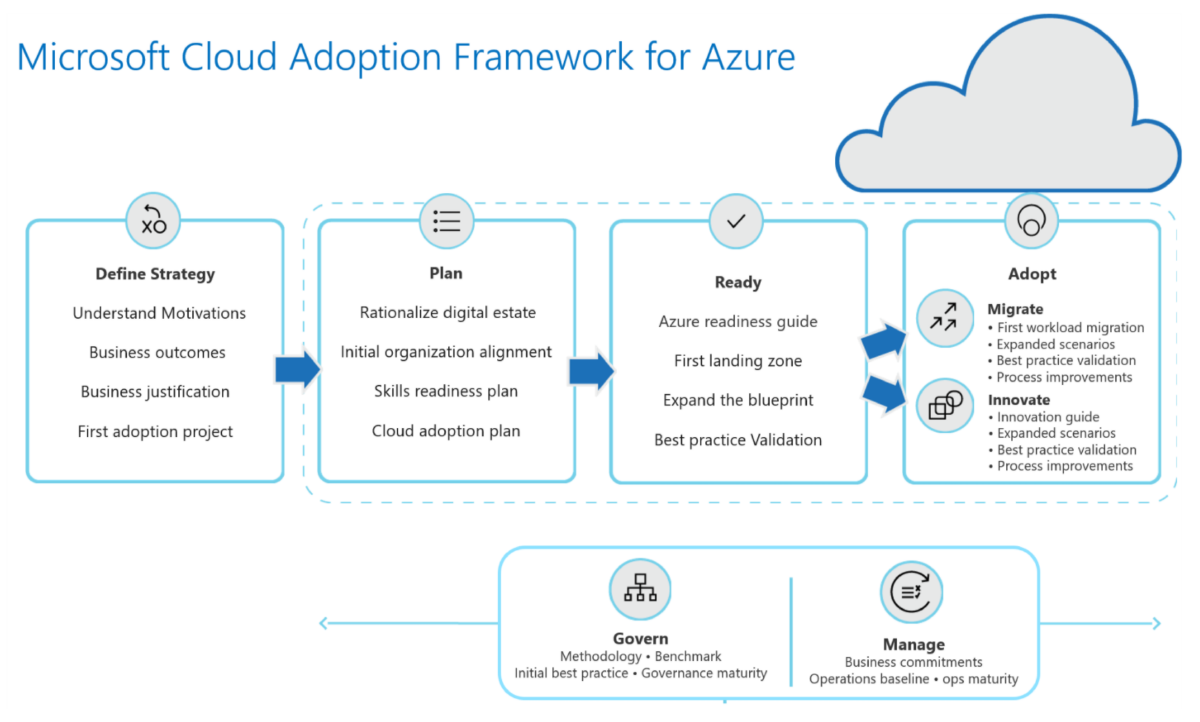
Cloud Adoption Framework (CAF)#
The Cloud Adoption Framework (CAF) has been crafted using essential feedback from partners and customers. This provides an excellent place to start as you begin planning. Of course, you don’t just land on the ideal design, but it helps to have a clear picture of where you are going.

The Microsoft Patterns & Practices site is another good Azure specific resource for understanding proven patterns and reference architectures.
The Island#
Webster defines island as ":an isolated group or area". There are a few variations of The Island, but one thing remains consistent; It has no connectivity to on-premises networks. This environment is completely isolated.
Island #1 - First Pass#
Every good story has a beginning. Many enterprises started their cloud journey many years back by simply setting up an account, doing some sandboxing, and just familiarizing themselves with the Cloud. You never know, one day that sandbox application could turn Production overnight! (Yes, I’ve seen this happen)
Usually, the first pass at a technology (especially as transformative as Cloud) isn’t going to be perfect. There are a lot of things you don’t know until you know. The main criteria that define our first pass at Cloud may include:
- Single Virtual Network; All dependencies self-contained
- Enterprise Apps and Data live in Data Centers (Owned or Colocation)
- No connectivity to on-premises networks; Environment is completely isolated
- Cloud Environment may not be under centralized I.T. control; They slow things down, right?
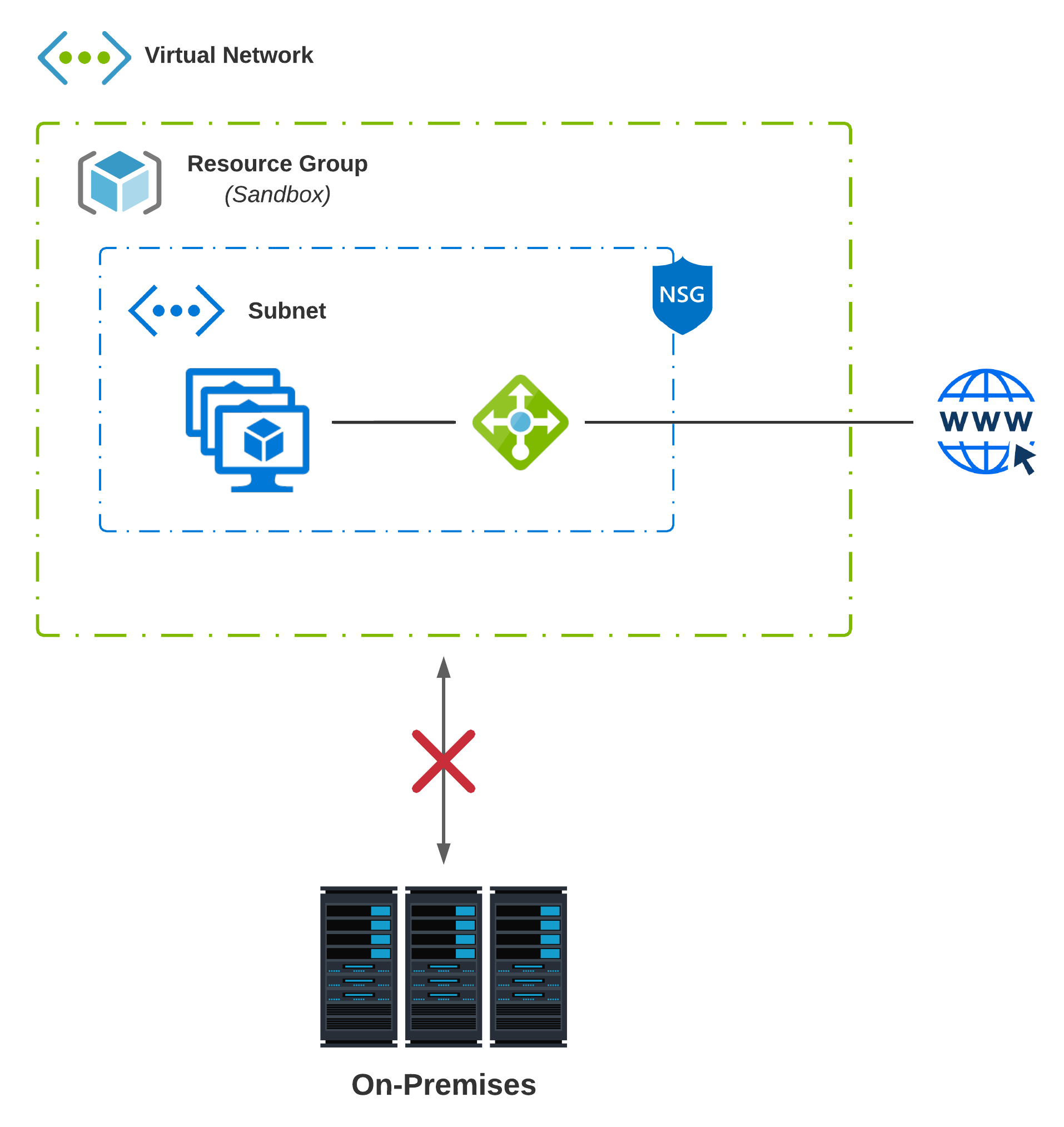
Island #2 - Cloud Native#
We are getting this whole cloud computing thing down now. We are super mature around security and governance, and we want to take full advantage of Azure-specific services. In this scenario, we don’t have any hybrid dependencies and focus on reliable and scalable infrastructure leveraging cloud native constructs in a single cloud-only. As a set of outcomes, this pattern aims to:
- Scale Out.and not up; Optimize based on consumption
- Multi-Region Active-Active design; Non-blocking asynchronous communication
- Embrace Stateless Application Design; Local state is considered an anti-pattern
- Use Internet as primary transport; State is shared between regions over cloud backbone
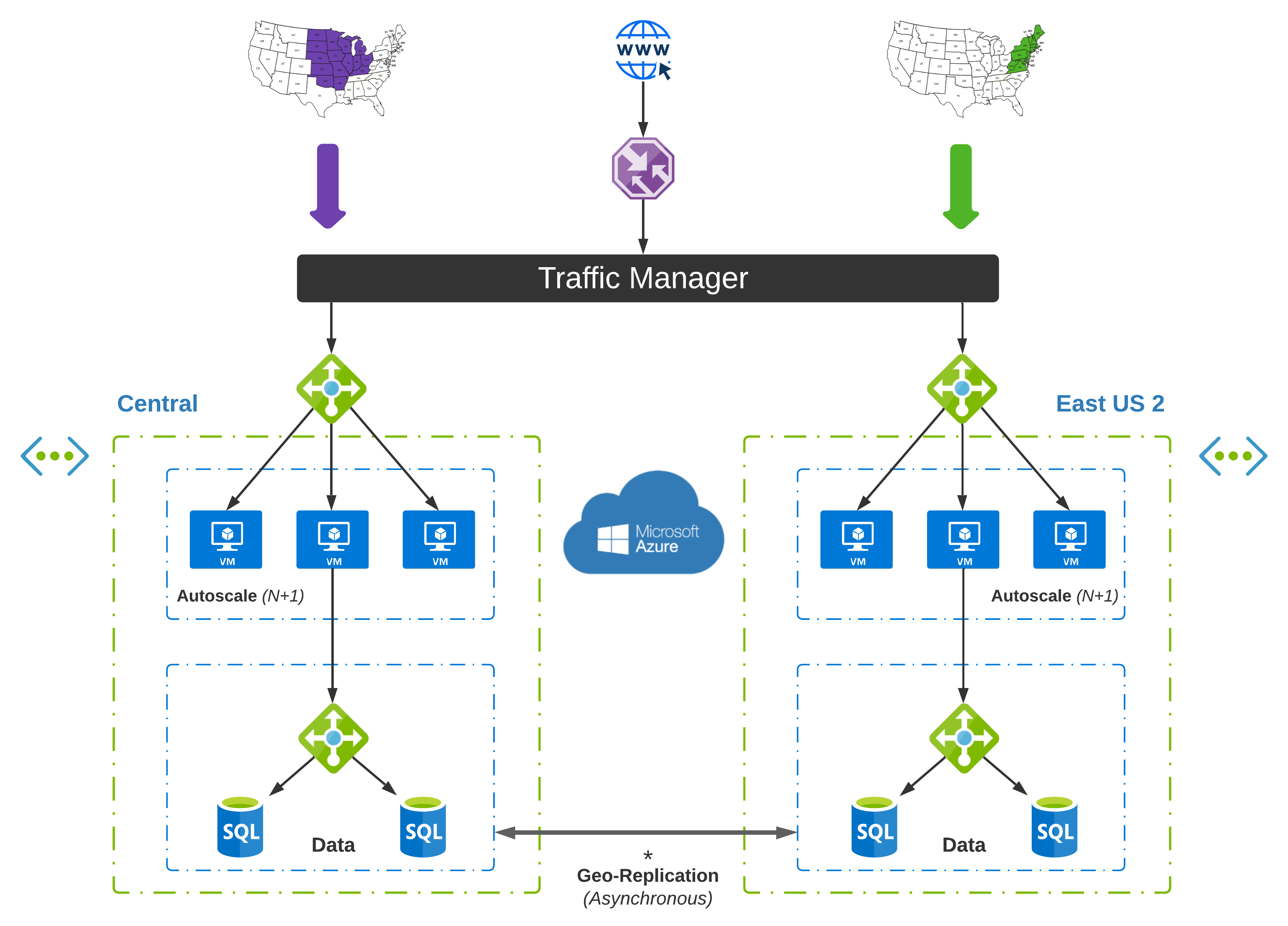
Our Cloud-Native Island is a best case scenario, but also unlikely at first for the traditional enterprise. This takes into account that your data lives in the Cloud, and you aren’t making any calls to backend services in your data centers. Data Gravity has proven to be a worthy antagonist in the quest to cloud native.
Hybrid#
Firstly, my definition of Hybrid Cloud is: Any workload that combines public cloud with an on-premises data center environment. Meaning, if for some reason, this public Cloud no longer has connectivity back to the data center, then the application(s) will not work.
At some point, that Island is going to get a little lonely. How can you possibly migrate anything without a reliable connection to Azure? I will forego the whiplash that generally takes place at this point in the story. That beautiful moment we all remember when server, network, and security experts first get involved.
So, we need a little bit of hybrid now. This is probably where things get the most complicated. There are many variations of hybrid, a plethora of options/considerations, and numerous maturity levels.
Hybrid #1 - Forced Tunneling#
Our first iteration of hybrid is met with much skepticism and minimal trust. This is why the obvious thing to do from the network and security space is to backhaul every packet to the data center to use existing routing, segmentation, deep packet inspection, file blocking, etc.
This practice is known as Forced Tunneling. It does precisely what is implied, e.g., it enables redirection of all traffic destined to the Internet back to your on-premises network.
- To accomplish this with ExpressRoute - Private Peering, advertise a default route from your BGP speaker and all traffic from the associated virtual network will be routed to your on-premises network.
- Doing this will force traffic from services offered by Microsoft like Azure Storage back on-premises as well; You will have to account for return traffic via Microsoft Peering or the public Internet.
- If Service Endpoints is configured, traffic is not forced on-premises and remains on Azure’s backbone network.
To accomplish Forced Tunneling over a Site-to-Site VPN, you would set up a User Defined Route to set the default route to the Azure VPN Gateway.
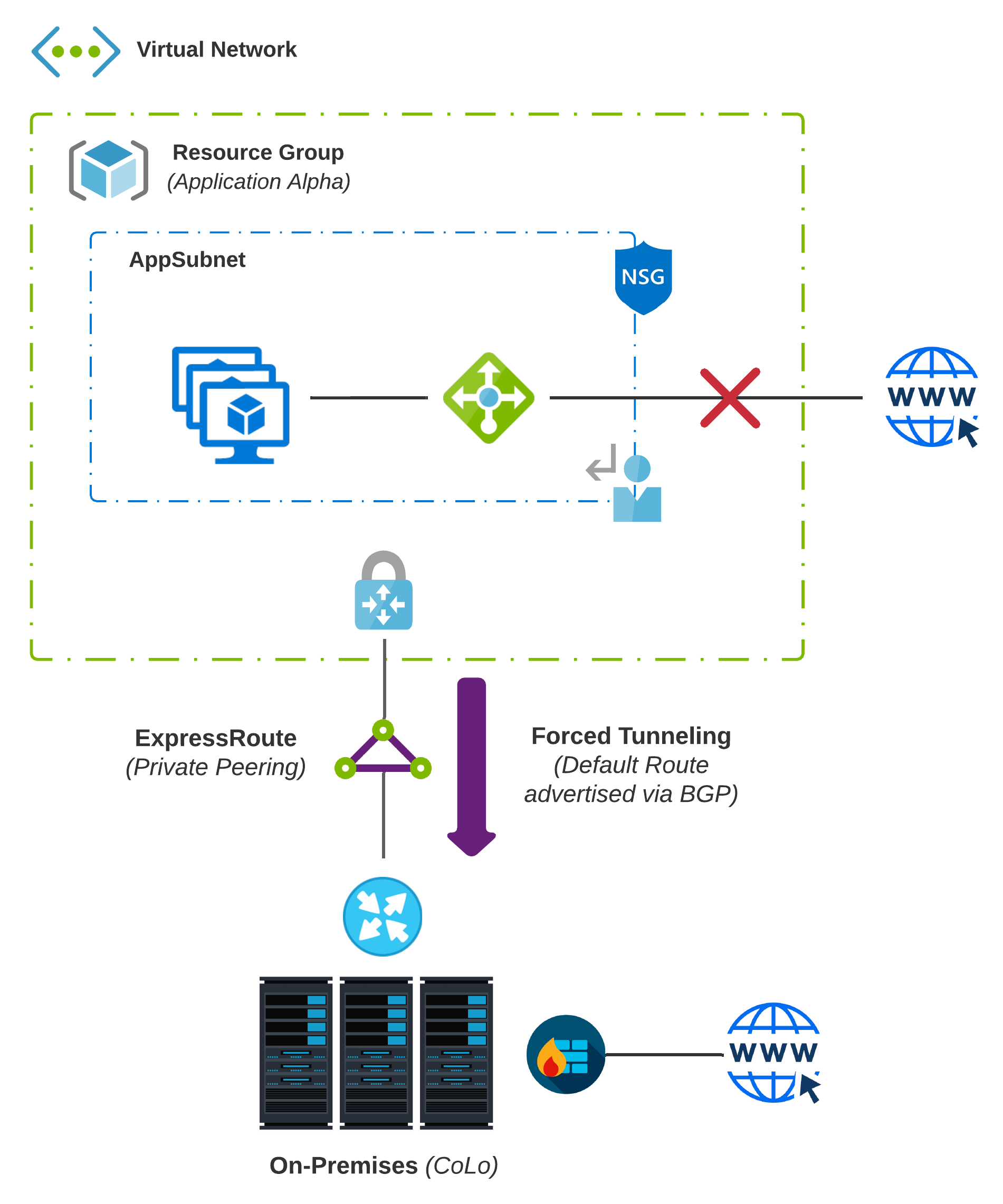
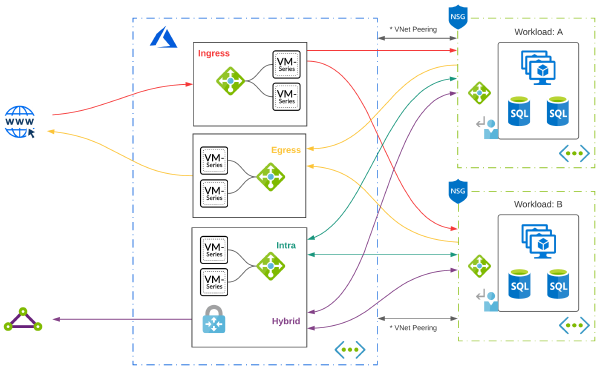
Hybrid #2 - Cloud DMZ#
For workloads in the Cloud, it makes sense to reduce dependencies on-premises (especially Internet) and keep as much traffic as we can in Azure. Also, to continue meeting various security requirements, often deploying Network Virtual Appliances (NVAs) will be necessary.
A common practice that accommodates future growth is routing egress and ingress traffic through separate scale sets. You can then use User Defined Routes for limited traffic engineering. For example, traffic destined to the Internet would use the private IP address of an internal load balancer as the next-hop.
In this scenario, Ingress represents inbound connections into the DMZ while Egress represents traffic destined to the internet. Another benefit of this design is additional throughput. VM-Series - Firewalls have come a long way but still have limitations that you must consider. You might also consider deploying an additional scale set for Transitive routing in substantial deployments.
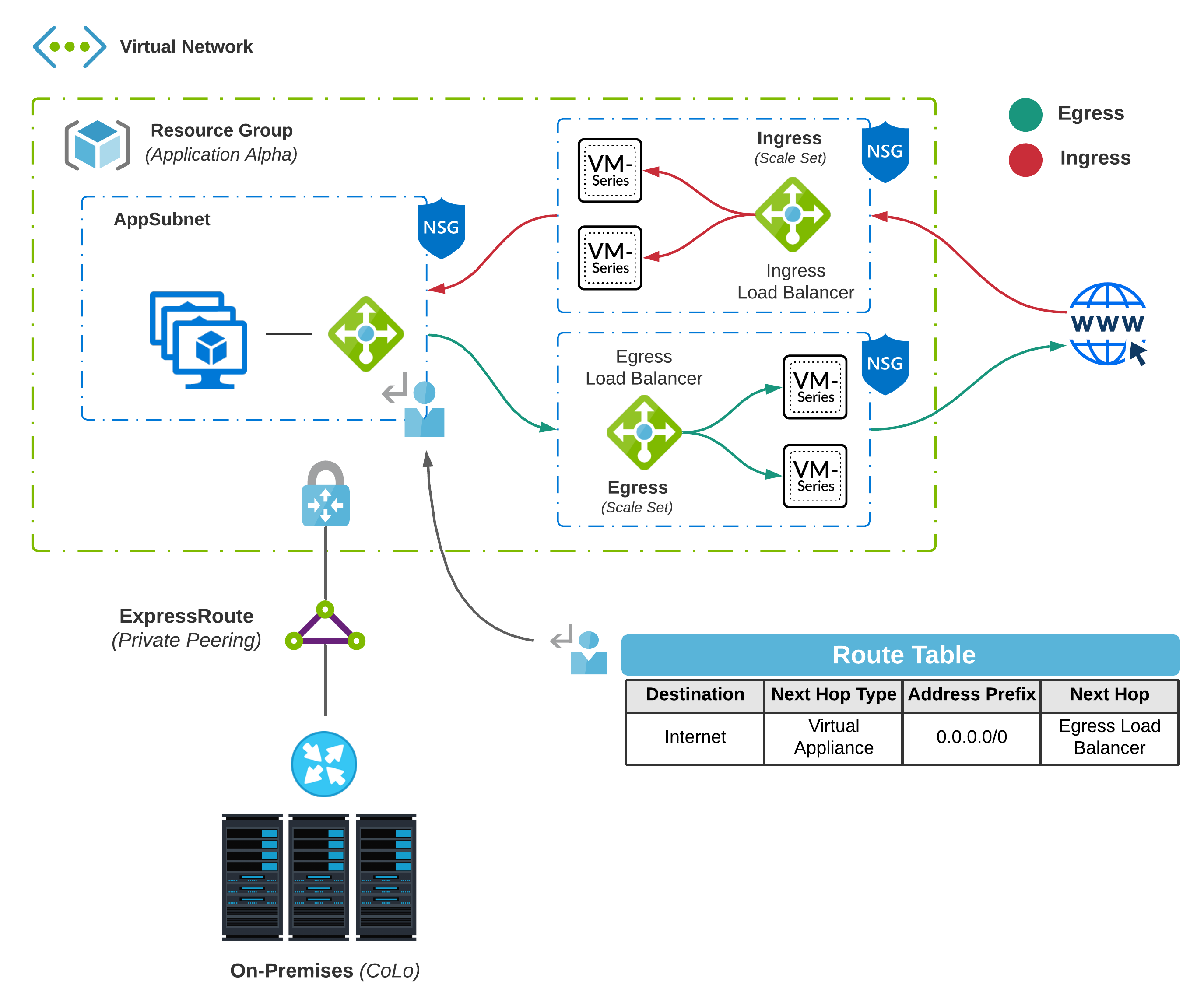
NVAs must be deployed in self-contained subnets. Deploying an appliance in the same subnet as your workloads and attaching a UDR to that same subnet may cause a routing loop.
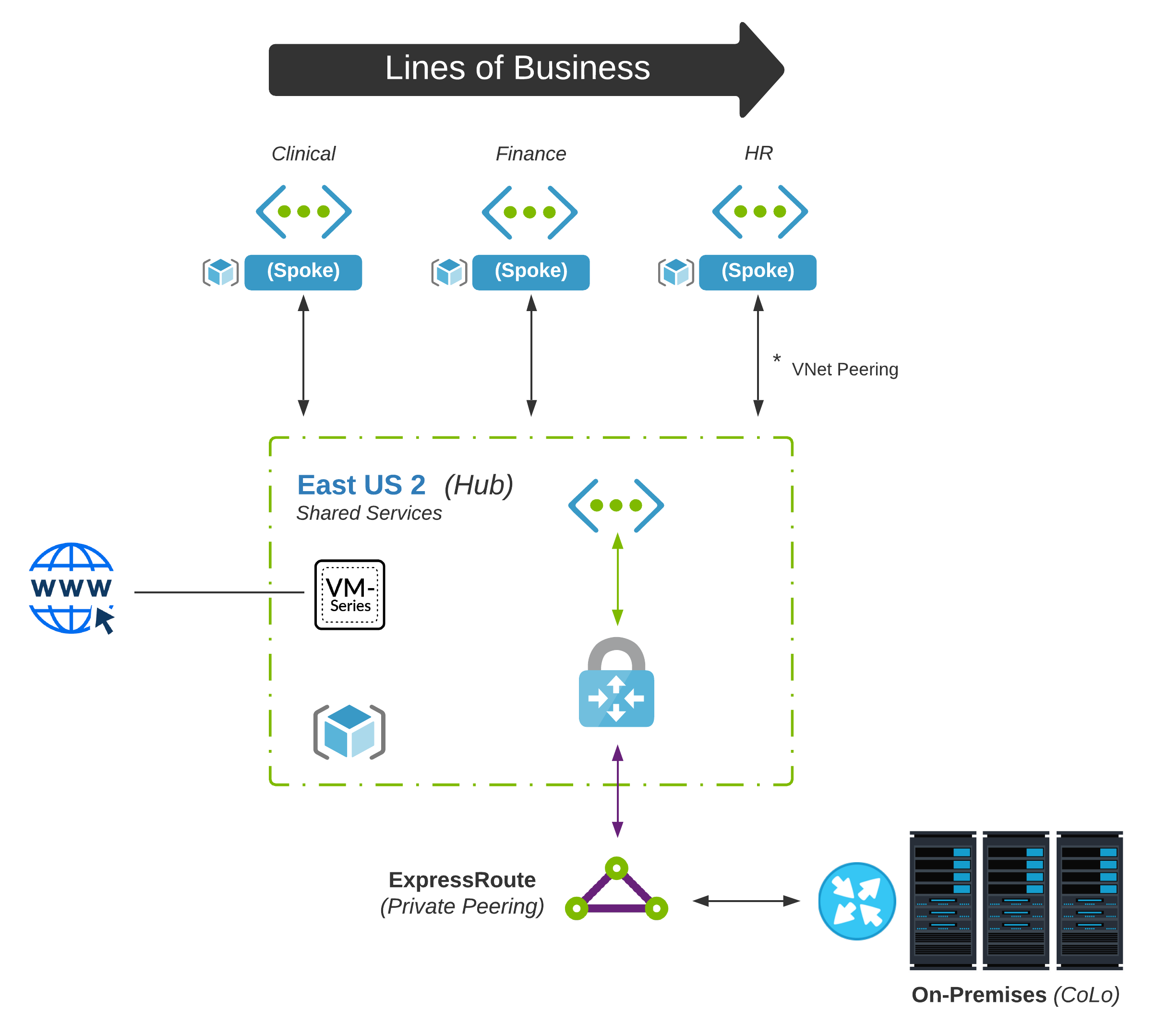
Hub & Spoke#
Until now, our patterns have been simple; Only a single virtual network has been referenced. In larger enterprises, this can get a little tricky. Over time as the Cloud grows, additional business units, centralized services, security, and even finance may start to leverage the Cloud. Sound governance is critical in managing adoption.
As consumption increases, subscriptions will likely grow. It is generally a good practice to model these constructs to match your organization’s hierarchy. As you follow this path, other virtual networks will be created. How is this challenge designed around while taking scale and governance in mind?
Centralized Hub#
Network practitioners are going to be very familiar with Hub & Spoke. Think about it like data center and branch office routing. We don’t want prefixes to be visible randomly all across the network. Aggregation is our friend here.
It is much more efficient to have summarization of routing for each site at the edge. It also makes sense to centralize certain services at the edge rather than deploy them at every office. Deploying NGFWs at every site would become expensive and challenging to manage. Our cloud hub will follow this same pattern. Any shared services that will be used across all spokes will live here.
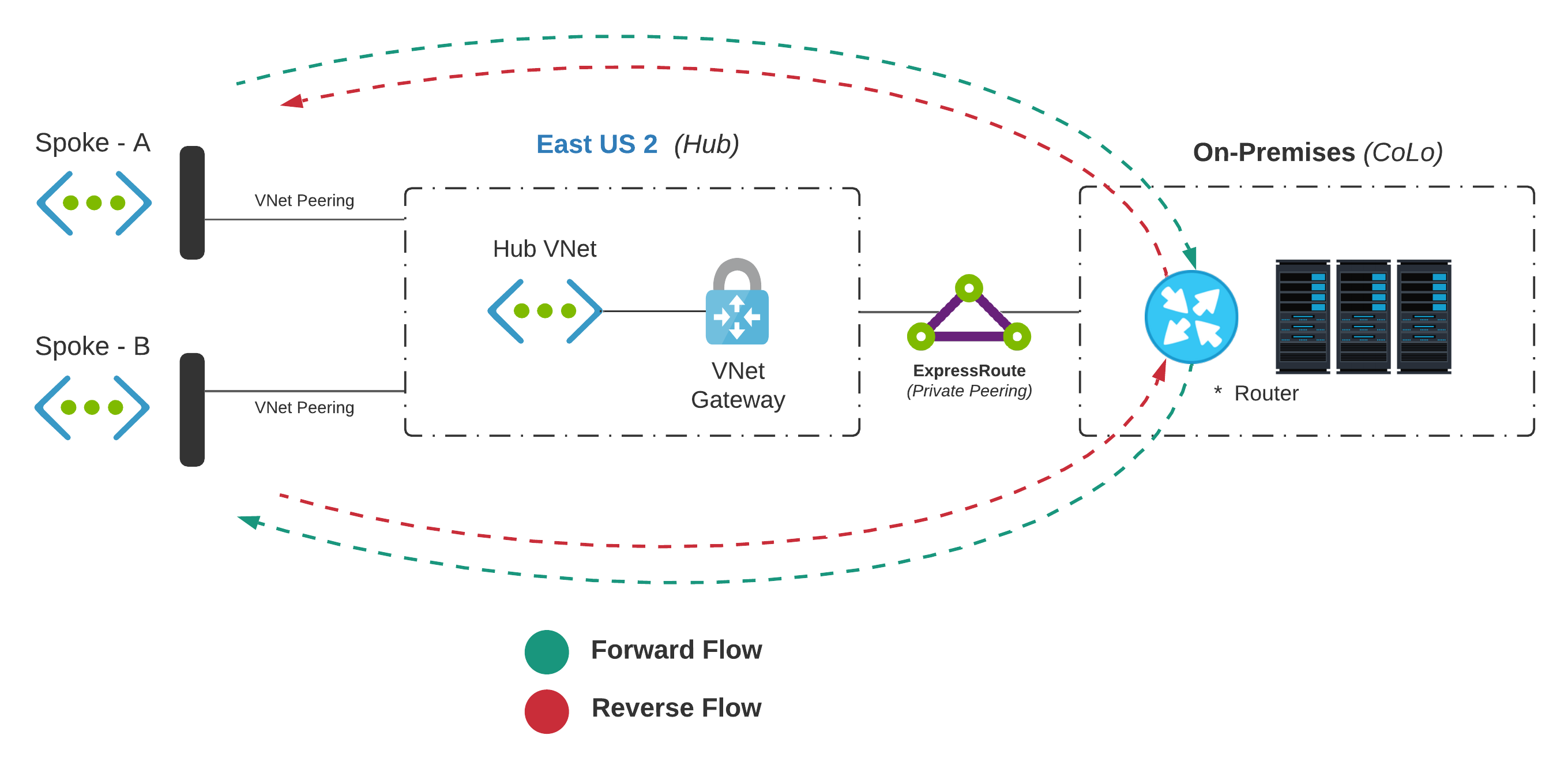
Spoke-To-Spoke Routing#
Now that multiple virtual networks are in play, how does traffic flow? Remember from Part 1 that VNets are non-transitive. For example, let’s say we have Spoke-A and Spoke-B which are VNet peered back to our hub. There have been two common approaches to solving this in the past:
On-Premises / CoLo - Routing#
This approach forwards traffic back to a physical device (That lives outside of Azure’s Cloud) that knows how to route packets. This approach is usually the first iteration as, if you already have hybrid connectivity, then these devices are already reachable.
- The Hub virtual network is configured to allow gateway transit; This enables peered virtual networks to use any attached virtual network gateways
- Each spoke should be configured to use remote gateways; This is required for traffic to use a gateway living in the virtual network you are peered with
- The router on-premises will handle any spoke-to-spoke routing; The existing BGP which was set up for private peering handles dynamic routing
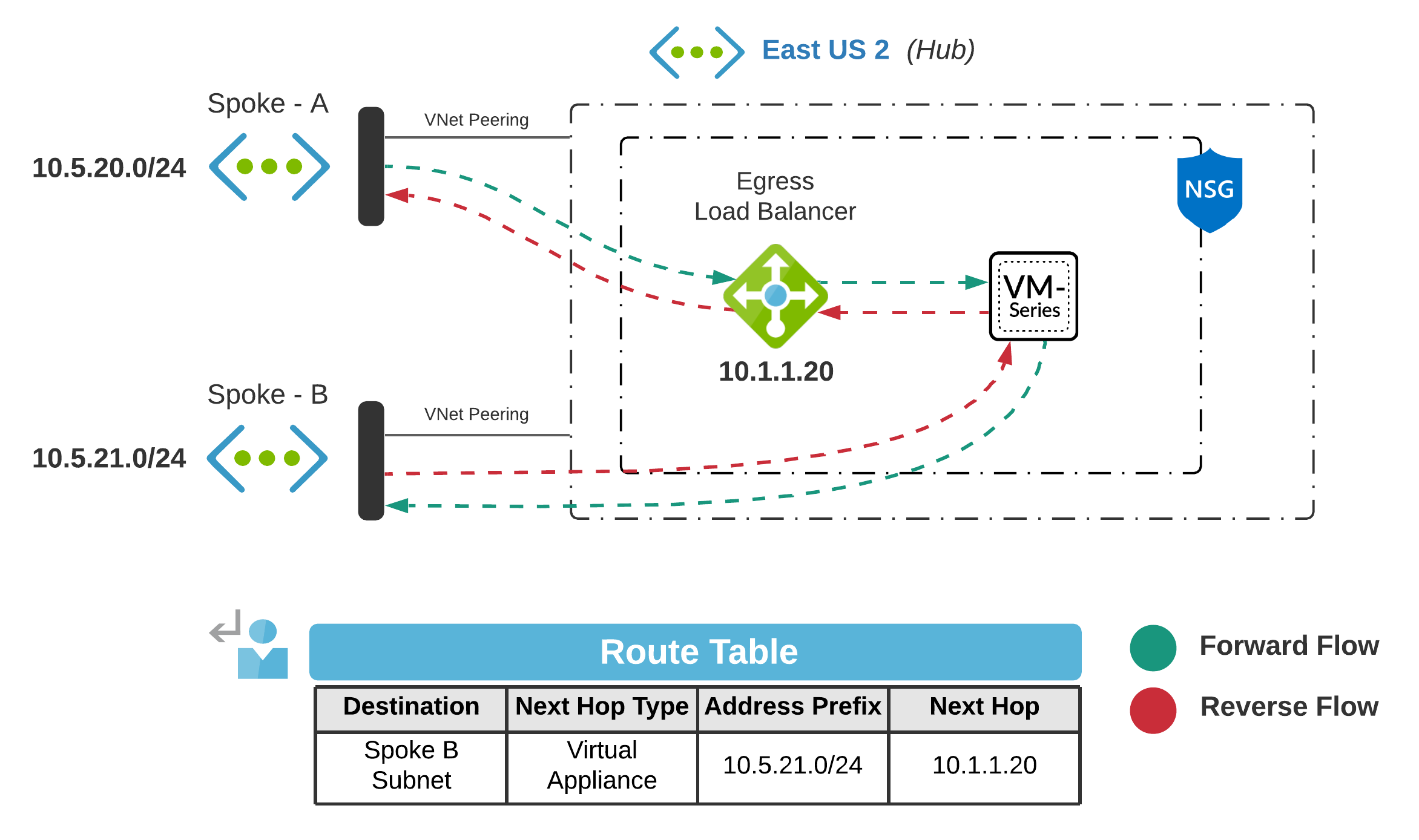
Network Virtual Appliance (NVA) - Routing#
Another option would be leveraging NVAs existing in the hub to route traffic between spokes. If we already have the Cloud DMZ design deployed, you would use UDRs to redirect traffic.
- Each subnet requires a UDR to steer traffic
- Destination matches the subnet prefix from the adjacent VNet
- Next Hop Type will be defined as Virtual Appliance (Next Hop Options)
- The Next Hop is the internal load balancer’s private IP (If deployed in a scale set)
Conclusion#
Why not just use a WAF for Inbound connections and Azure Firewall for Outbound? It all comes down to what requirements you are working with and the capabilities needed to meet them.
NextGen Firewalls have more capabilities today and are also being used heavily in the enterprise. Many will opt to extend these capabilities into the Cloud. Microsoft currently has Azure Firewall - Premium in Public Preview, which should close the gap a little more.
If this material was valuable, check out Part 1 to learn more about the fundamentals. In Part 3, we will dig into ExpressRoute design along with breaking down a few things I wish I would have known before jumping in the deep-end.
Acknowledgements#
Big thanks to the wise and resourceful Steven Hawkins for taking the time to peer review this post. Your feedback is always insightful and appreciated.