
The necessity for protocols to keep communication secure has been around since the dawn of the internet. The first ever VPN was jointly developed by a vendor consortium (which included Microsoft) in 1996, and came in the form of Point-to-Point Tunneling Protocol. Although many are skeptical about the value of VPNs in 2022 and beyond, customer consumption of cloud provider VPN services have paved the way for additional features and exponential scale.
What impact do innovations like Transit Gateway and Accelerated VPN Connections have on design complexity, network performance, and operations? In this blog, I will look back at the first time I deployed a site-to-site VPN and then examine what is possible today when thinking through network design. This is going to be two parts.
My First Experience#
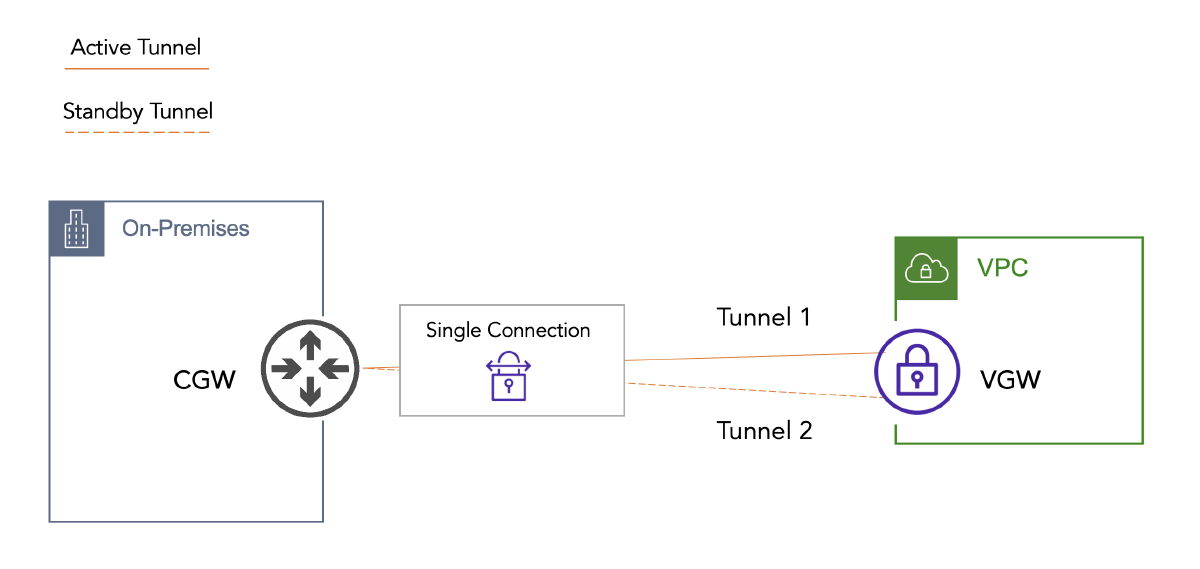
Site-to-Site VPN in AWS is a fully managed and highly available service. This comes in the form of two endpoints on the AWS side (public IP addresses in different AZs per one VPN connection). This service is charged hourly per connection (plus data transfer charges). My first experience connecting on-premises to AWS looked something like this:
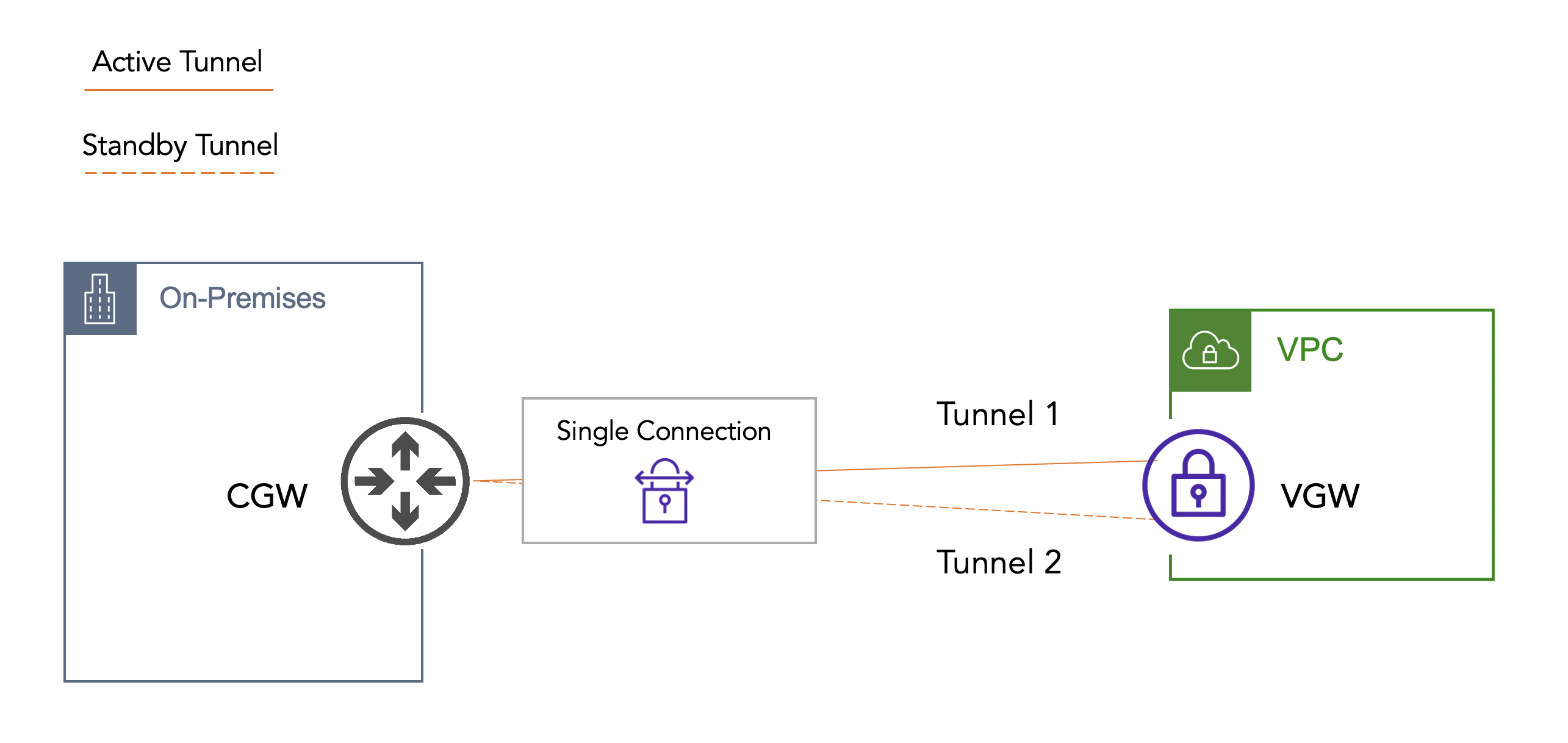
This was long before the public cloud had disrupted enterprise infrastructure. In this case, we had a single VPC that required connectivity back to on-premises. Since the application being developed wasn’t production, we set up a single VPN connection to a single physical router in the Data Center. This was easy work since, as network engineers, we pushed VPNs like weights. And we had an existing B2B process in place, so our paperwork + process was ready. Somewhere along the way, though, this application went into production.
Making it Highly Available#
Pre Transit Gateway, you would typically see a Virtual Private Gateway and VPN connection from each VPC back to on-premises devices. If you follow best practices and want the highest availability possible in this scenario, you will also have redundant devices on-premises. This means you would end up with 2x VPN connections, which totals 4x VPN tunnels per VPC. Once the application went past QA, to meet our requirements for Tier 0 infrastructure, we needed high availability.
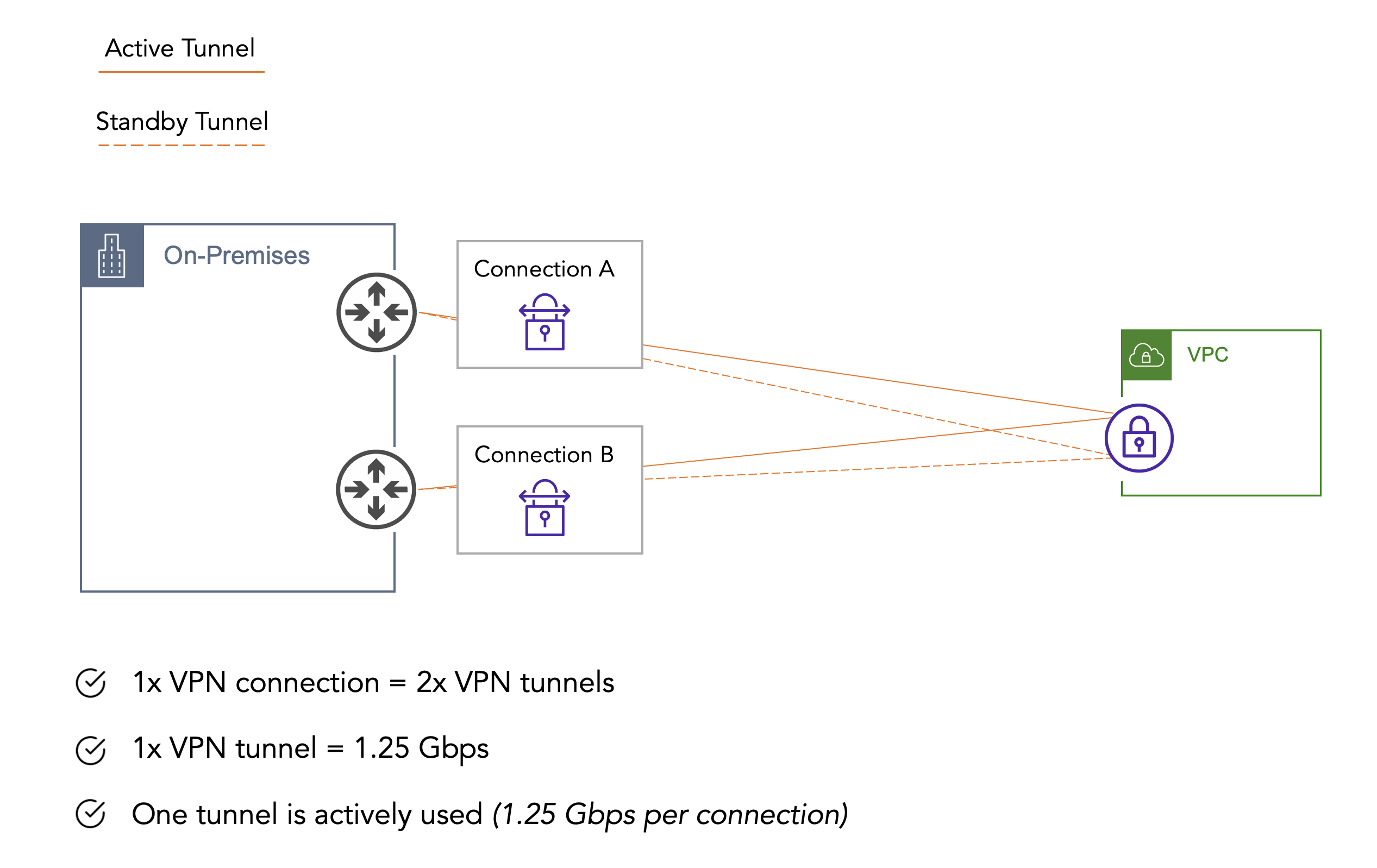
One question I could always count on getting from developers when we would onboard this design was: “Since we have four tunnels here, why can’t we forward traffic on all of them?” The simple answer is that you can override defaults and forward traffic across all tunnels to AWS from on-premises; however, the VGW will always select a single tunnel for return traffic.
Growth, Scale, and Operations#
At some point, Digital Transformation (you may have heard of it) caused crazy fast growth. And with that growth came more VPCs. And with those VPCs came the necessity for connectivity back to on-premises. Say we add just two additional VPCs using the above methodology, and we end up with 6x VPN connections, bringing us to 12x VPN tunnels to manage.

The above example is single region with only 3 VPCs. The reality for many organizations using AWS is much larger. What would this design look like if we had 50 VPCs? What happens when we need to include multi-region for DR capabilities? How does it impact operations when an application has performance issues, and the network is getting blamed?
Conclusion#
As we onboard more VPCs, it becomes apparent that the above design does not easily scale. Bandwidth is limited, tunnels increase exponentially, and operations will have limited success in diagnosing network problems (or proving the network is not the problem). In Part 2 we will dive into how Transit Gateway and Accelerated VPN Connections take this from an operational misstep to an enterprise success story.